Serverless Apache Airflow with AWS MWAA
At Vumi, we update daily market data of all kinds and from multiple providers, such as prices, events (dividends and splits), asset allocation (by sectors, countries, categories…), market changes (delisted stocks, ticker changes), and many other things. This involves millions of pieces of data that we ingest, process, transform, and load into our databases every day.
However, most of these ETL processes only need to be run once a day. So we set up an architecture that would allow us to have an Apache Airflow available only the hours we needed it. How did we do that?
Vumi is deployed on AWS, and this provider offers MWAA (Managed Workflows for Apache Airflow) as a solution for deploying an Airflow environment. It uses an S3 bucket to store DAGs, requirements, and other necessary files. In addition, it allows environments to be monitored with CloudWatch, which is very useful when the environment is not active.
However, AWS does not offer a Serverless implementation of the MWAA environment, but when the environment is deleted, all components, including the database, are completely removed, losing metadata and other configuration information such as roles and permissions, as well as logs of DAG executions. This makes it very complicated to create and destroy an environment every day. At the same time, having a continuously active environment is inefficient, as it consumes resources even when no tasks are being processed.
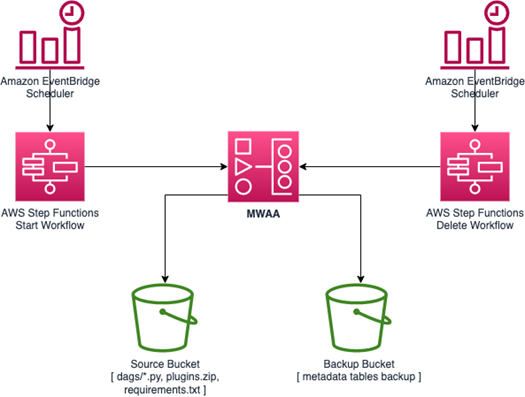
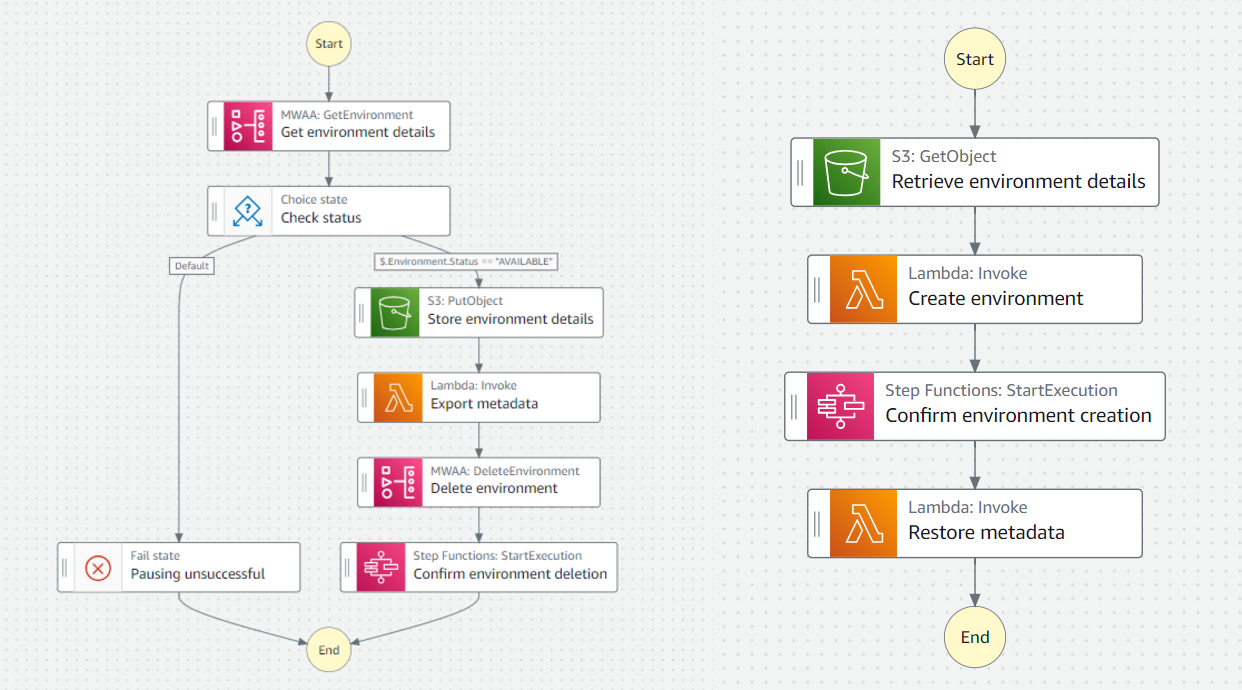
To solve this, we use two processes that create and import, and export and delete environment details before and after DAG scheduling. These two processes are orchestrated with Step Functions and scheduled with EventBridge. To save the data, a DAG pauses execution and exports in S3 all information from the active DAGs to a CSV file.
The next day, a similar process retrieves the configuration of the exported environment and uses it to recreate it. When the creation is finished, another DAG restores the active DAGs.
The concrete implementation has two additional stacks. One of them polls the environment to verify its creation or deletion, and to know when to run the metadata export and import DAGs. The other uses EventBridge and SNS to send notifications when part of the process fails.
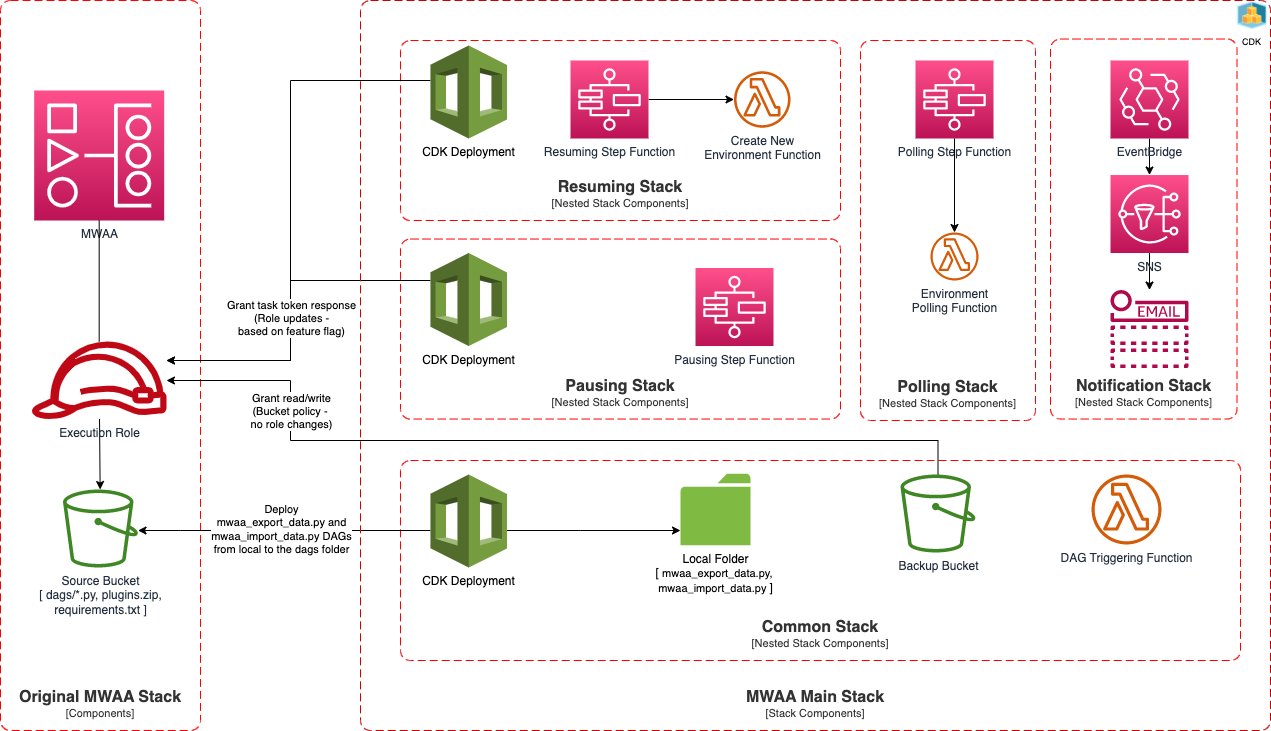
The complete export and re-import flow is as follows:
- EventBridge Scheduler starts the execution of the pause Step Function at the time scheduled by a Cron expression.
- GetEnvironment from the AWS SDK retrieves the details of the active environment.
-
The environment-backup.json object is saved to the backup S3. This file contains the environment configuration, such as Airflow version, configuration options, the S3 path of the environment DAGs, number of workers…
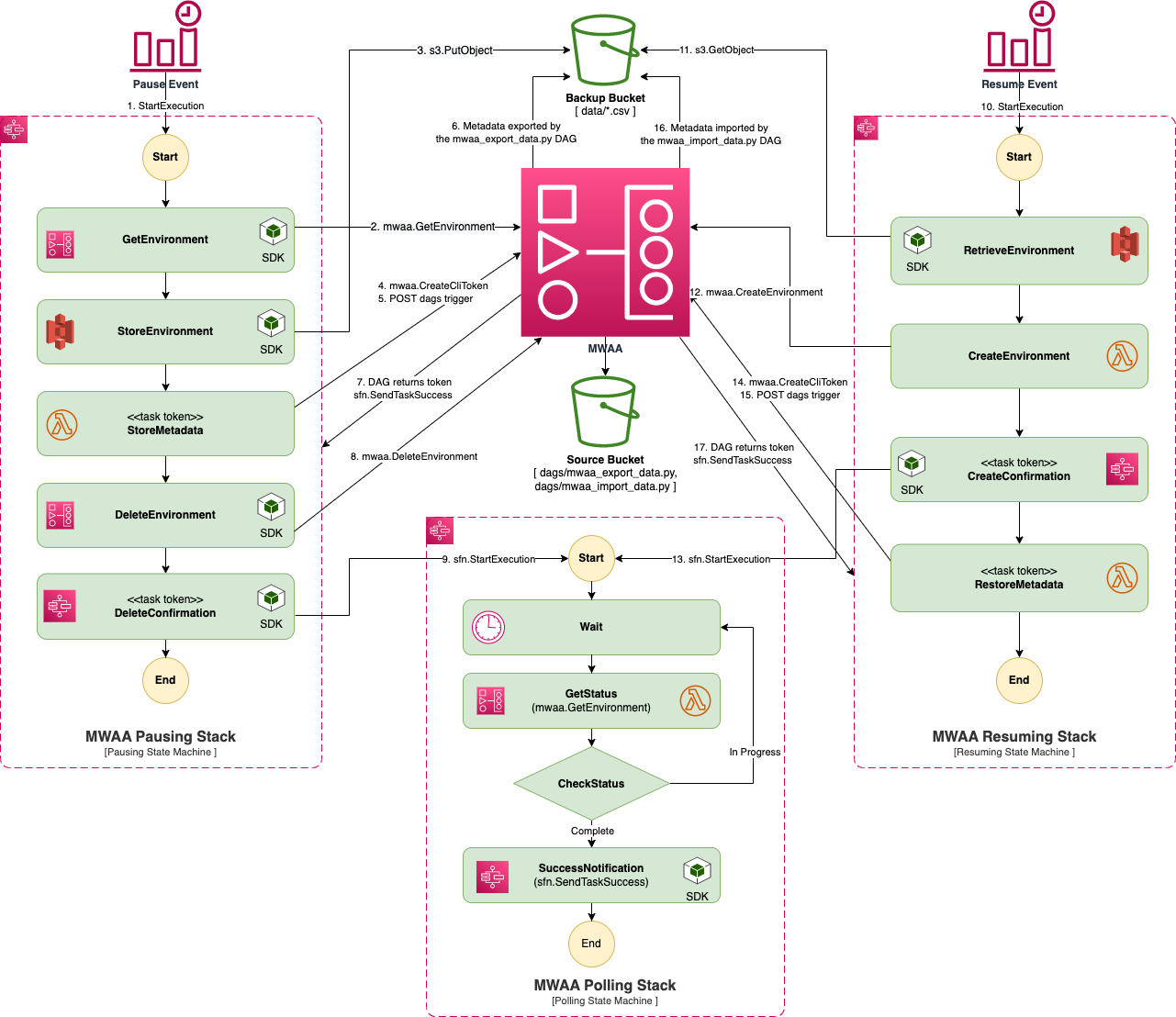
- A token is created for the export DAG.
-
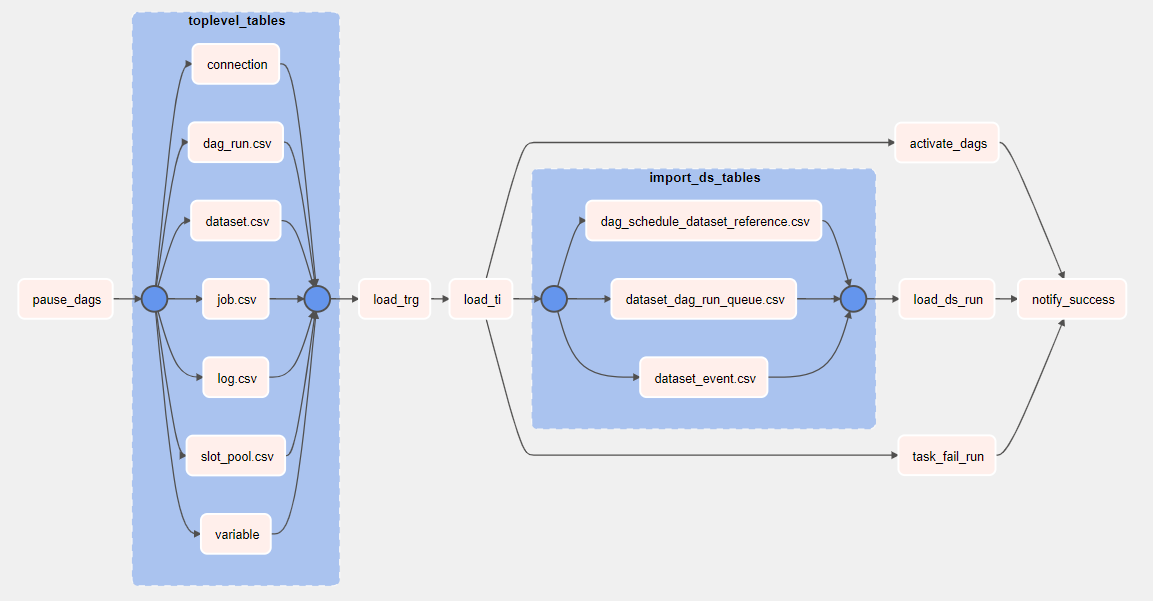
The StoreMetadata lambda starts the export DAG in the still active environment. This DAG pauses the running DAGs, and exports all Apache Airflow data and variables. If it fails, it reactivates them.
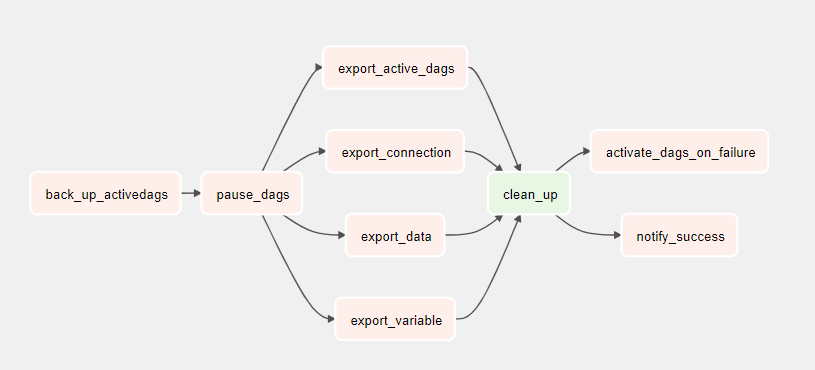
-
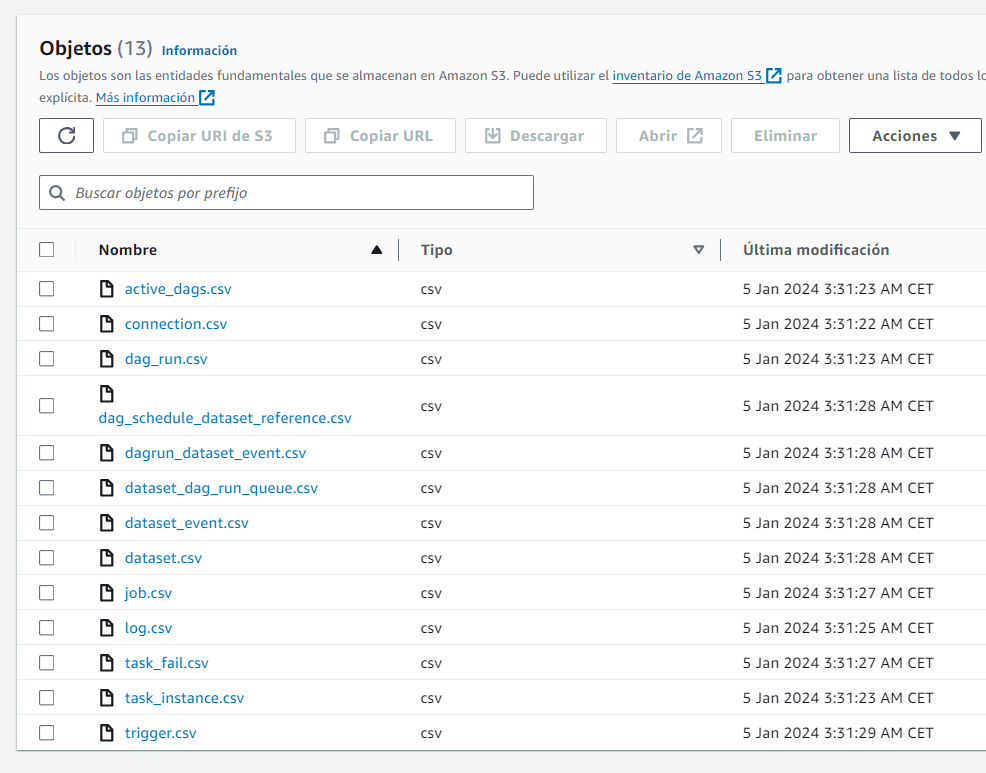
Environment metadata is exported to S3 in multiple CSVs.
- The export DAG notifies the Step Function of the success.
- The environment is removed via the AWS SDK.
- The polling step function periodically checks the status of the environment until successful deletion is confirmed.
To recreate the environment the next day, the process is similar, although in this case an additional lambda is used to create the environment with the information from the previously exported environment-backup.json.
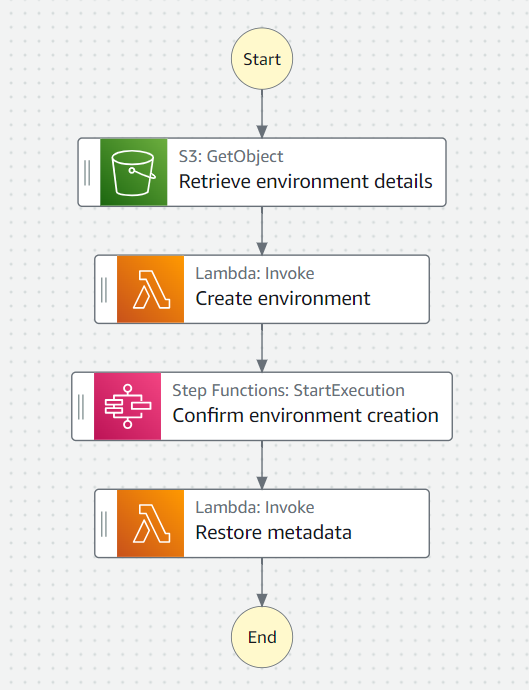
The last lambda invokes the re-import DAG when the environment finishes creating. This DAG reads the exported CSV files from S3 and re-imports it into the Airflow database, thus activating the DAGs and resuming the execution of the environment.
This solution saves up to 87.5% of the cost of the environment compared to running it continuously without implementing the automation explained above.
In the long term, it will be necessary to extend the time we need the cluster active, especially when non-daily ETL processes are required. At the moment, these continuous processes are few and light, and we do not use MWAA for this.
If this sounds like a useful solution, AWS provides an implementation in its GitHub repository, although we had to make changes to resolve some issues it had. For example, the CSV export and read CSV had inconsistencies that periodically caused DAGs to be disabled. Also, backups grow after many cycles, and it is necessary to periodically clean the environment’s databases.